
本ページの具体的にJリーグのデータ分析を行う方法を紹介。下記ページも参考
How to analyze?その① 分析戦略 – Jリーグデータ分析(FC東京中心)
開発環境としてはクラウドを前提に開発を行うため、Google Colabで対話方式で実装を進め、実行結果をGoogle driveに保存する形をとる。また、スクレイピングの時間短縮やスクレイピング先の付加削減のため、スクレイピングしたデータはCSVで保存し、分析する際は保存したCSVを読み込んで分析することとする。
#取得したデータを修正し、CSVに保存
df_team.to_csv(BOOK_NAME_CLUB)
df_player.to_csv(BOOK_NAME_PLAYER)
#修正したデータを読み込み、分析に用いる
df_player = pd.read_csv(BOOK_NAME_PLAYER)
df_club = pd.read_csv(BOOK_NAME_CLUB)分析したデータはソースコード上でグラフ化し、EXCEL等は用いなかった。この辺は好みの問題(EXCEL等のほうが綺麗にしやすいが、反復動作には向かない)もあるが折角なのでPythonをベースに分析を行った。下記は実行例。グラフをコードで書くのは割と面倒くさい…が、全チームなど反復してみたいときはやはりコードペース(Matplot)の方が可視化しやすい。
def show_participation_by_age(df_club, team_name):
df_ft = df_club.query('チーム名 == @team_name').set_index("年度")
fig, ax1 = plt.subplots(1, 1, alpha=0.5, figsize=(12,6), )
ax2 = ax1.twinx()
bottom = 0
cm = plt.get_cmap("Blues")
col_array = ["U20出場率", "U24出場率", "U28出場率", "U32出場率", "U36出場率", "O36出場率"]
i = 2/ len(col_array)
for col in ["U20出場率", "U24出場率", "U28出場率", "U32出場率", "U36出場率", "O36出場率"]:
if col == col_array[-1]:
ax1.bar(df_ft.index, df_ft [col], label = col, bottom = bottom, color = "k")
else:
ax1.bar(df_ft.index, df_ft [col], label = col, bottom = bottom, color = cm(i))
bottom += df_ft [col]
i += 1 / len(col_array)
ax1.set_title(f"{team_name}の年代別出場時間率")
ax1.set_xlabel("")
ax1.set_ylabel("年代別出場率")
ax1.xaxis.set_major_locator(MultipleLocator(1))
ax1.legend(loc='upper left', bbox_to_anchor=(1.1, 1))
ax2.plot(df_ft.index, df_ft["総合順位"], color = [0.6, 0, 0])
ax2.set_ylabel("総合順位")
ax2.yaxis.set_major_locator(MultipleLocator(1))
ax2.set_ylim([1, 20])
plt.gca().invert_yaxis()
plt.show()
show_participation_by_age(df_club, "FC東京")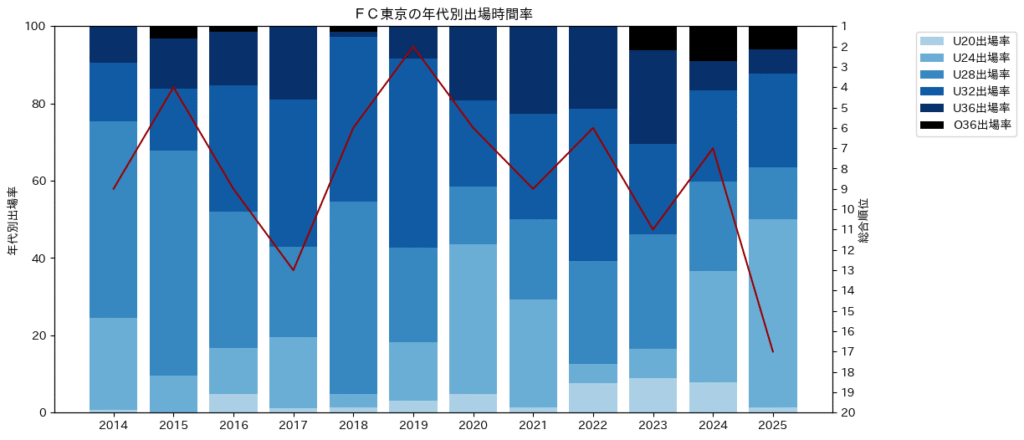
データの保存方法はいくつか考えられるが、個人的にはクラブデータと選手データの2種類に分けて保存。リーグ統計はクラブデータ統計からすぐに計算できるので、保存はしなかった。下記が選手データとクラブデータの中身。
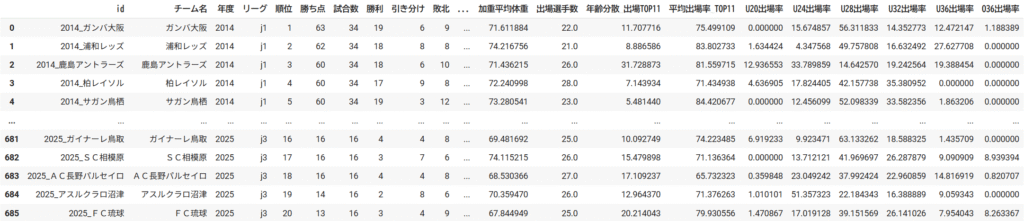
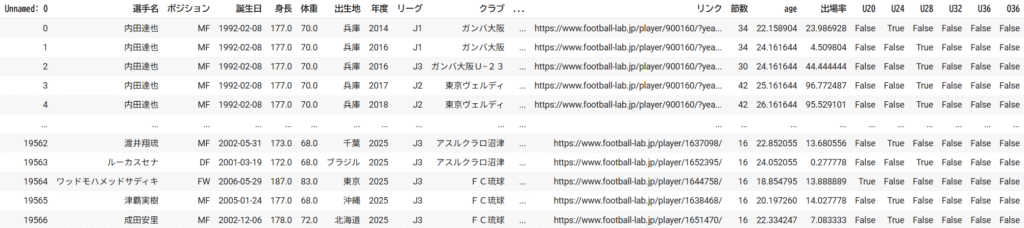


コメント